Published on
Claude Fable 5 公开发布:把那个会自己写攻击的模型,装上锁交给所有人
上一篇里那个会自己挖漏洞、写攻击的恐怖模型,两个月后公开发布了,名字叫 Fable 5,价格还砍了一半多。一边喊'这玩意危险',一边把它放出来——这事到底怎么圆的?这篇从零讲清楚 Mythos 和 Fable 5 是什么、强到什么程度、以及它凭什么敢公开。

上一篇我们见识了一个会自己挖零日、自己写完整攻击链的模型——Mythos Preview,看完多少有点后背发凉(没读的话,先看这里)。两个月后,2026 年 6 月 9 日,同一套底子的模型公开发布了,叫 Fable 5,价格还不到当初的一半。
等一下——前脚刚说「这能力危险得该警惕」,后脚就把它摆上货架,这不自相矛盾吗?这篇就从头讲清楚这件事,假设你之前完全没听过这些名字也没关系。
一、先把名字理清楚:一套技术,为什么要起两个名字
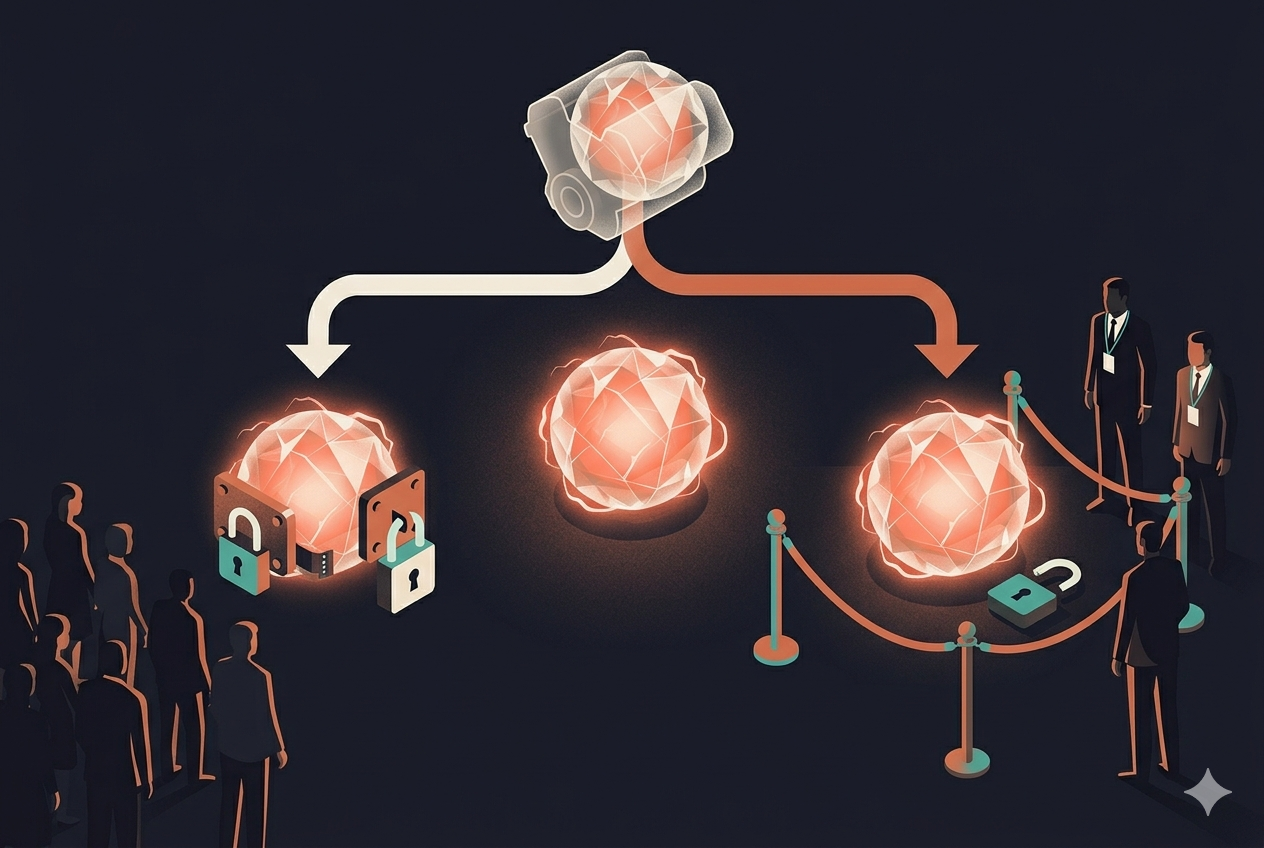 刚接触的人最容易在名字上绕晕,我们先把三个词排好队:
刚接触的人最容易在名字上绕晕,我们先把三个词排好队:
- Mythos Preview:2026 年 4 月的内部预览版,从没公开过,就是上一篇那个被红队拿去当黑客使的家伙。
- Mythos 5:Mythos Preview 的正式升级版,面向少数授权用户、把安全限制松开的版本。
- Fable 5:和 Mythos 5 用的是同一套底子,但额外焊了一圈安全护栏,是给大众用的公开版。
打个比方你就懂了:这就像同一台赛车引擎,出了两个版本。一个装了限速器、卖给所有人——这是 Fable 5;另一个解开限速、只发给有执照的车手——这是 Mythos 5。引擎是同一台,差别只在那把锁松没松。
记住这个「同引擎、不同锁」的画面,整件事就顺了——后面会反复用到它。按官方的说法,这两个版本的能力,都超过了此前任何一个公开发布过的 Claude,在几乎所有能力测试上都是当前最强。
二、它到底强到什么程度:几乎每张考卷都考了最高分

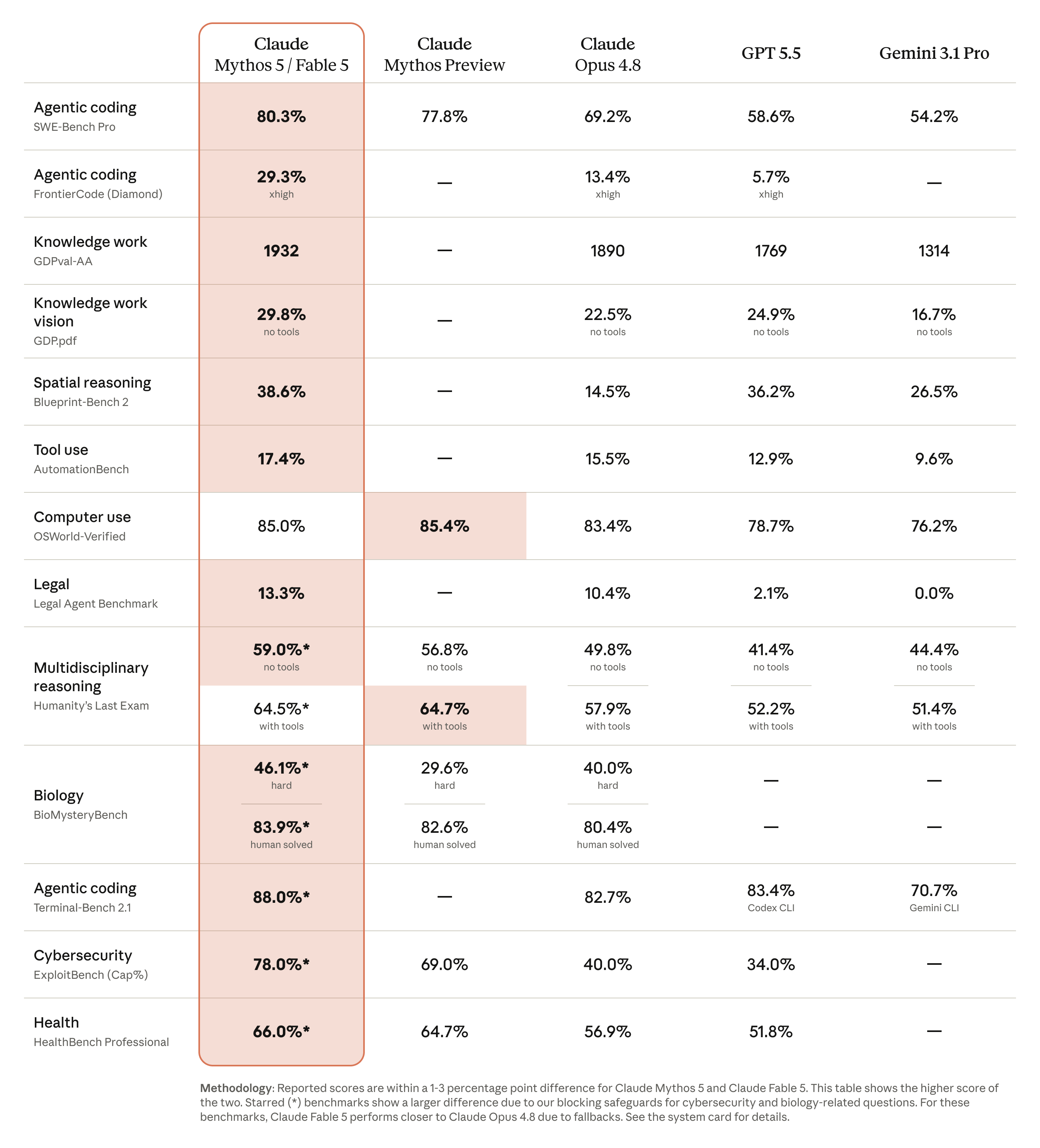
图(来自官方公告):在编码、知识工作、视觉、计算机操作、生物、健康等十几项测试里,Mythos 5 / Fable 5 大多领先。带星号的几项因为撞上了网络安全 / 生物护栏,Fable 5 会退回到接近 Opus 4.8 的水平。
「全球最强」这种词听多了容易麻木,不如看几个具体场景,你立刻就有感觉了。
写代码。有个叫 SWE-Bench-Pro 的测试,是拿真实开源项目里的真实问题来考模型——「这有个 bug,你自己改对它」。Fable 5 考了 80.3 分(满分 100)。更直观的是一个真事:支付公司 Stripe 用它一天干完了原计划要两个月、涉及 5000 万行代码的大改造。两个月压缩成一天,这不是快一点,是换了个量级。
搞科研。这是这代模型蹿得最猛的方向:
- 设计蛋白质的活儿,它干得比以前快了约 10 倍,14 个目标里有 9 个做到了熟练科学家的水准;
- 让分子生物学家盲评(不告诉他们哪个答案是 AI 出的),约 80% 的情况下,他们更喜欢它提出的研究思路;
- 一项基因研究里,它自己跨 138 种动物做分析,最后训出来的模型,比已经发在《Science》上的成果还好,个头却小了 100 倍。
看图。它能从一张科研图表里把数据抠出来,能照着一张截图把网页重新搭出来,甚至只靠眼睛看就通关了《宝可梦:火红》——要知道,以前的模型得拄一堆辅助工具的拐杖才玩得动。这说明它「看图」已经接近「看懂」了。
记性好、扛得住长任务。它能在几百万字的篇幅里不走神。一个有意思的对照:玩卡牌游戏《杀戮尖塔》时,给它配上一个能「记笔记」的外置记忆,它的表现比 Opus 4.8 直接好了 3 倍——因为它会把打过的经验记下来,跨越很长的流程慢慢攒优势。
这些测试各考一面:有的考真刀真枪改代码,有的考看图,有的考长线规划和记性。但它们指向同一个结论——这不是某一项偏科突进,是全科一起往上抬。
三、它凭什么敢公开:把危险能力关进三道闸
 现在回到开头那个别扭的问题:上一篇里这套底子能自己挖洞、写攻击,那把它公开,不等于把枪发给街上每个人吗?
现在回到开头那个别扭的问题:上一篇里这套底子能自己挖洞、写攻击,那把它公开,不等于把枪发给街上每个人吗?
官方的答案就藏在那个比喻里——公开的是装了限速器的版本。新焊上的安全机制,正是这次敢于放开的前提。这圈护栏由三道闸组成。先说清楚「闸」是什么:它其实是一个专门盯梢的小模型,杵在主模型的前后两头,实时判断「这个问题/这段回答,危不危险」,危险就拦下。
- 网络安全闸:一旦你的问题涉及挖漏洞、搞攻击,主模型不接茬,而是把球踢给 Claude Opus 4.8,让那个更老实的模型给你一个安全的回答。上一篇里那些攻击本事,在 Fable 5 这儿,就是被这道闸挡住的。
- 生物 / 化学闸:大面积拦截生化武器相关的问题。举个能看出分寸的例子——Mythos 5 在预测某种病毒外壳怎么拼装上,水平甚至超过了专门干这个的模型;这种能力,搞科研是宝、被滥用是祸,所以被划进了闸内。
- 防偷师闸:拦那种「海量提问、想把它的本事偷学到别的模型里去」的行为(行话叫蒸馏)。
闸结不结实,得让人来砸。综合内部测试和外部 1000 多小时的悬赏挑战,没人砸出一个通用的破解口;外部用 30 种公开的越狱套路轮番上阵,有害的单轮请求一条都没得逞;英国的 AI 安全研究所短测了一下,说「取得了一些进展」(也就是还没真正破开);一家合作方更直接,说 Fable 的护栏是「测过的所有模型里最稳的」。
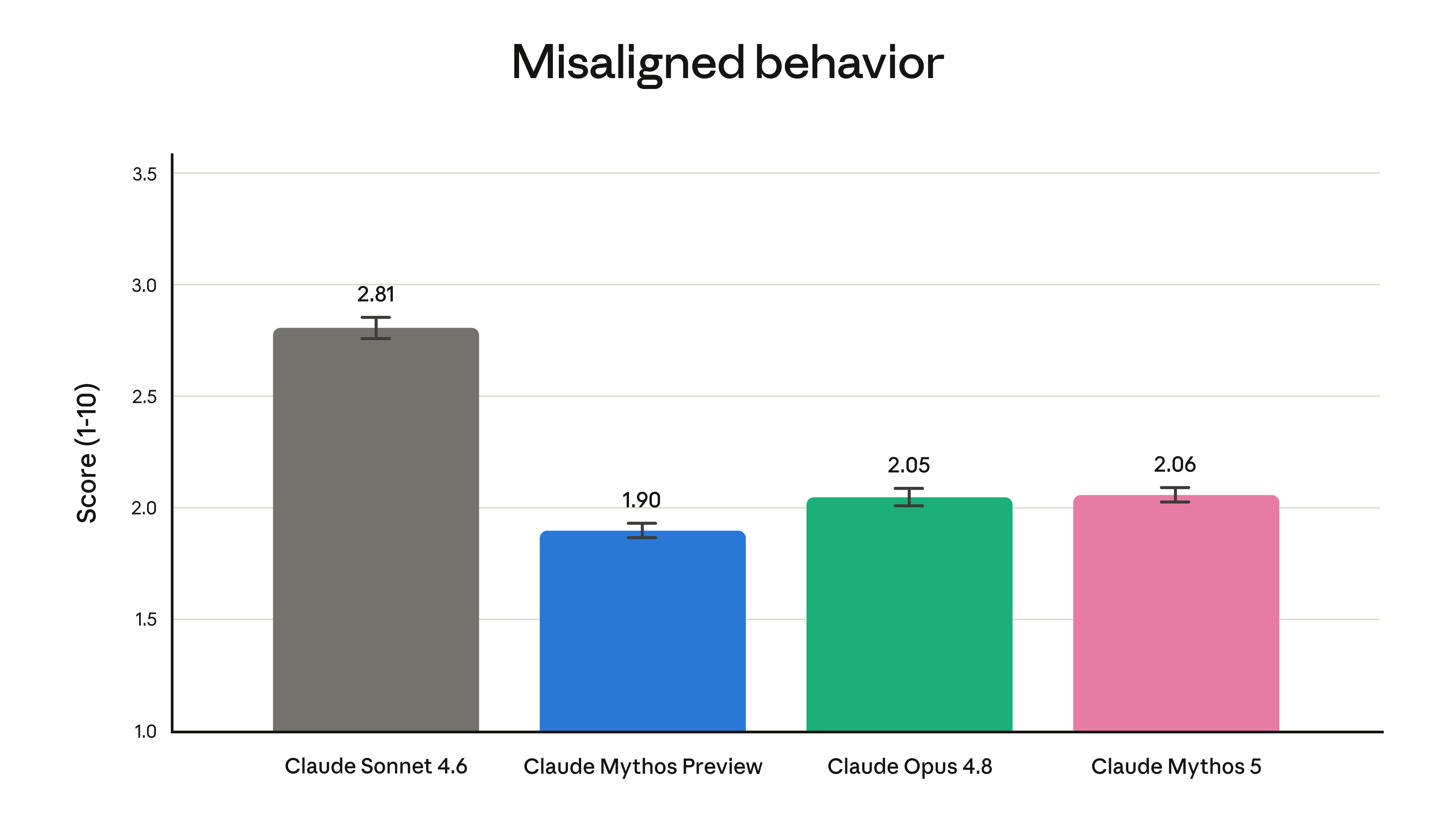
图(来自官方公告):失准行为评估,分数越低越好。Mythos 5 是 2.06,跟 Opus 4.8 的 2.05 几乎一样,明显比 Sonnet 4.6 的 2.81 好。
除了「别被人带坏」,还得「自己别跑偏」。在专门测「模型会不会自作主张干不该干的事」的评估里,Mythos 5 拿了 2.06(越低越好),和 Opus 4.8 的 2.05 基本贴平——本事涨了一大截,但「品行」没有退步。配套还有数据上的承诺:这类高能力模型的对话只留 30 天、绝不拿去训练模型,还加了访问记录和删除保护。
一句话收住这一节:这圈护栏不是发布之后再打的补丁,它本身就是「能不能发布」的入场券。
四、多少钱、谁能用、想解锁怎么办

- 价格:每一百万个输入字符收 10 美元、输出 50 美元,不到 Mythos Preview 的一半。能力翻番、价格腰斩,这是这代模型最实在的变化之一。
- Fable 5 谁能用:API 和按量付费的企业版立刻能用;订阅套餐(Pro / Max / Team 这些)分批放——6 月 9 到 22 号免费送着用,23 号起改成消耗额度,等算力跟上了再恢复。
- Mythos 5(解锁版)怎么拿:不向大众普发,而是分人群逐步开——搞网络安全的,通过 Project Glasswing 项目先用上;做生物研究的,走可信访问计划(且只对生物 / 化学松闸)随后开放;更大范围的可信用户,再慢慢扩。
说白了,「谁能用全力版」被做成了一道准入题:公开渠道拿到的,是上了锁的 Fable 5;想解锁,得先证明你是个可信、有正经用途的人。
写在最后
 把这两篇连起来看,会发现 Anthropic 其实在演示一种新玩法。
把这两篇连起来看,会发现 Anthropic 其实在演示一种新玩法。
过去发模型,往往是道单选题:太危险就压着不发,够安全才放出来。而 Fable 5 和 Mythos 5 给了第三个选项——同一身本事,按你是谁、拿去干嘛,发不同的版本:公开的夹紧,可信的解开。安全,从一道发布前的关卡,变成了让发布本身成立的设计。
这也意味着,真正的分界线悄悄挪了位置:不再是「这模型有多强」,而是「谁,拿到了哪个版本」。当 Fable 和 Mythos 共用一台引擎、只差一把锁,风险防得住防不住,就全压在了那把锁和发钥匙的人身上。
上一篇结尾我担心的,是「攻击方已经武装到牙齿、防守方还在搭架子」的危险窗口。这次公开放出来的,恰恰是被限速的 Fable 5,全力版还攥在受控的小圈子里——可以说,官方主动把那段危险窗口管了起来。能不能一直管住,就看这把锁、和发钥匙的规矩,扛不扛得住能力一代比一代猛的冲击了。
这大概是接下来最值得盯着看的地方。
参考资料
- Anthropic,Claude Fable 5 and Claude Mythos 5,2026 年 6 月 9 日:https://www.anthropic.com/news/claude-fable-5-mythos-5
- AWS,Anthropic Claude Fable 5 on AWS: Mythos-class capabilities with built-in safeguards now available
- 前序:本站《Mythos Preview 网络安全能力报告》、Project Glasswing(负责任披露与受控解锁)