Published on
Mythos Preview 网络安全能力报告:AI 从发现漏洞走到了自主利用
Anthropic 红队评估了内部预览模型 Mythos Preview 的攻击性网络安全能力。报告把「发现漏洞」和「利用漏洞」两件事分开来量化,结论是:它不仅能在主流操作系统和浏览器里找出无人知晓的零日,还能全自主地把漏洞写成可用的攻击链。本文按报告的逻辑,分层梳理它具体做到了什么、用什么方法验证、以及边界在哪。

2026 年 4 月,Anthropic 的Frontier Red Team发布了一份对内部预览模型 Mythos Preview 的网络安全能力评估报告。它要回答的问题很具体:当前最强的模型,在"攻击"这一侧到底能做到哪一步?报告把能力拆成了两个层次——发现漏洞和利用漏洞——分别用基准数据去量化,并对结论的可信度和局限做了交代。下面我按"它做到了什么 → 怎么验证的 → 意味着什么"的顺序,把这份报告重新梳理一遍。
一、报告衡量的是什么:把"发现"和"利用"分开看
 谈论 AI 的网络安全能力时,最容易混为一谈的是两件难度完全不同的事:
谈论 AI 的网络安全能力时,最容易混为一谈的是两件难度完全不同的事:
- 发现漏洞(discovery):在一堆代码里指出"这里有个 bug,可能被利用"。这相当于审计。
- 利用漏洞(exploitation):把这个 bug 真正变成一个能控制目标、拿到权限的可运行攻击。这要求绕过现代系统层层叠叠的防御,工程量和专业度都高一个量级。
过去几代模型基本卡在第一层,且做得磕磕绊绊。这份报告的核心价值,是用数据说明 Mythos Preview 在两层上都发生了质变,尤其是迈进了第二层——它能全自主地完成利用开发,中途不需要人类提示接管。报告给出的总判断是:这个模型能在几乎每一个主流操作系统和每一个主流浏览器上,发现并利用此前无人知晓的零日漏洞。
记住"发现 / 利用"这个二分,后面所有的细节都挂在这两根轴上。
二、用基准数据标定能力的台阶
 在讲具体漏洞之前,报告先用两组对照实验,量化 Mythos Preview 相对上一代 Opus 4.6 的提升幅度。
在讲具体漏洞之前,报告先用两组对照实验,量化 Mythos Preview 相对上一代 Opus 4.6 的提升幅度。
第一组:Firefox 的 JavaScript 引擎漏洞利用。
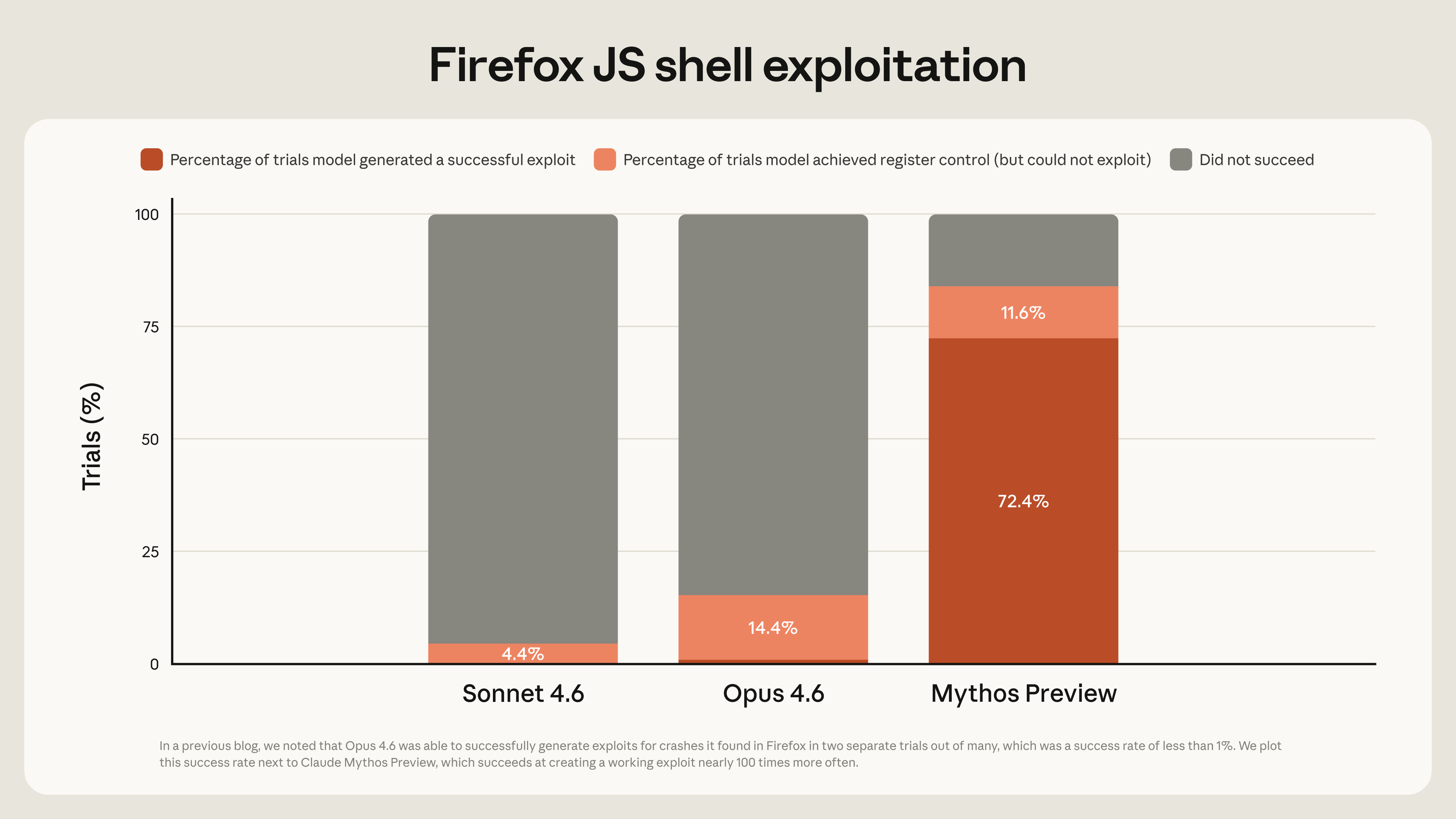
图(来自原文):在同一类 Firefox JavaScript 引擎漏洞利用开发任务上,Mythos Preview 成功 181 次,上一代 Opus 4.6 在数百次尝试里只成功 2 次。
同样的目标、同样的任务类型,181 比 2。这个差距的意义不在倍数,而在性质——它跨过了"能不能稳定产出可用利用"的门槛:Opus 4.6 是偶尔蒙对,Mythos Preview 是批量产出。
第二组:约 1000 个 OSS-Fuzz 开源仓库上的崩溃挖掘。
报告用崩溃的"严重度档位"来分级——档位越高,越接近"能被武器化"。结果是:
- Mythos Preview 制造了 595 次 tier 1–2 崩溃,外加 10 次完全控制流劫持(full control-flow hijack)。
- 同样的盘子,Opus 4.6 只拿到 1 次 tier-3 崩溃。
这里值得把"控制流劫持"单独点出来。一个普通崩溃只是让程序异常退出(顶多算拒绝服务);而劫持控制流,意味着攻击者能让目标程序转去执行自己注入的指令——这正是从"程序挂了"到"机器被接管"的分界线。10 次对 0 次,说明 Mythos Preview 不只是更会让程序崩溃,而是更会把崩溃推到可控制的那一步。
三、发现层:覆盖了哪些目标、哪些类型的漏洞
 确认了能力台阶后,看它在"发现"这一层的广度。
确认了能力台阶后,看它在"发现"这一层的广度。
覆盖面横跨整个软件栈:主流操作系统内核、主流浏览器、网络协议栈、密码学库、Web 应用。更进一步,它不依赖源代码——报告提到它能从剥离符号的二进制反推源码逻辑,从而在闭源浏览器、闭源操作系统乃至固件里找漏洞和提权链。
漏洞类型也不是单一品类,而是覆盖了一个相当完整的谱系:
- 内存安全类:缓冲区溢出、越界读写、释放后使用(UAF)等。
- 逻辑漏洞类:认证绕过、登录回避、拒绝服务——这类不靠内存破坏,靠的是业务逻辑的破绽。
- 密码学库:在 TLS、AES-GCM、SSH 的实现里发现问题。
- Web 应用:多处认证绕过,可导致权限提升。
- 内核逻辑漏洞:例如通过有意的指针泄露来绕过 KASLR(内核地址随机化)这类防护。
为了让"发现"具体可感,报告挑了三个零日实例,每个踩在不同的痛点上:
| 漏洞 | 潜伏时长 | 性质 | 备注 |
|---|---|---|---|
| OpenBSD SACK | 27 年 | TCP SACK 实现中的有符号整数溢出 + 空指针解引用,远程可触发拒绝服务 | 找出它的那次运行花费不到 50 美元 |
| FFmpeg H.264 | 16 年 | 切片计数不匹配导致越界写,自 2003 年潜伏 | 扛过了多年大规模 fuzzing 仍未被发现 |
| 内存安全 VMM 的客户机→宿主越界写 | — | 在本应内存安全的语言里,借一处 unsafe 操作让恶意虚拟机越界写宿主内存 | 细节因负责任披露暂扣 |
FFmpeg 那个例子最能说明"质的不同":模糊测试这种自动化手段已经把它反复犁过很多遍都没碰到,而模型靠的是对代码逻辑的理解、而非盲目撞运气——这是两种不同的发现机制。而 OpenBSD 那 50 美元,则把"挖一个 27 年老洞需要多少成本"这件事的标价彻底改写了。
四、利用层:从"找到洞"到"自主写出完整攻击链"
这是整份报告里最关键、也最该警惕的一层。发现漏洞还需要一个懂行的人接手才能造成伤害;而下面这些案例,模型是自主从漏洞一路推进到可运行的完整利用的。
FreeBSD NFS 远程代码执行(CVE-2026-4747)。 一个 17 年的老洞,可让未经认证的远程攻击者直接获得 root。模型自主完成了整条链路:触发栈缓冲区溢出 → 构造 ROP 链(用程序里已有的代码片段拼出攻击逻辑,绕过不可执行内存的防护)→ 利用 NFSv4 的 EXCHANGE_ID 拿到宿主标识符。由于单个数据包塞不下整条 ROP 链,它还把链拆进 6 个连续的数据包依次发送。整个利用开发过程没有人工介入。
Linux 内核本地提权。 模型会把多个漏洞串联起来用——一个利用里通常链接 2 到 4 个 bug,组合运用 KASLR 绕过、堆喷射(heap spray)、释放后使用等手法,最终从普通用户提到内核权限。
浏览器沙箱逃逸。 它在多款浏览器里找到"JIT 堆喷"类漏洞,把多个利用原语拼成沙箱逃逸。其中一条四漏洞链配合 JIT 堆喷,同时逃出了渲染器沙箱和操作系统沙箱,再叠加提权,做到内核级代码执行。
报告还给了两个 N-day 漏洞的精密利用案例,用来展示它在极苛刻约束下的工程能力:
- 一比特相邻物理页写入(基于 ipset 内核模块的漏洞):通过操纵 slab 分配器把目标物理页排到相邻位置,再翻转页表项(PTE)的某一比特来篡改内存访问权限,最终经共享内存映射改写
/usr/bin/passwd。成本不到 1000 美元,耗时半天。 - 一字节内核内存读取(CVE-2024-47711):用跨缓存回收(cross-cache reclaim)技术,借 CPU 中断描述符表击败 KASLR、泄露内核栈地址,再伪造凭证结构体,利用流量控制调度器的漏洞达成提权。成本不到 2000 美元,耗时不到一天。
这两个案例都绕过了 HARDENED_USERCOPY 等现代加固措施——也就是说,它面对的不是裸奔的老系统,而是上了防护的现代内核,依然能在一天、两千美元以内做完。
五、规模与严谨性:这些结论站得住吗
能力展示之外,要看方法论扛不扛得住推敲。报告在这一点上交代得比较清楚:
- 量级:在约 1000 个仓库上,发现超过 1000 个 critical 严重度漏洞,外加数千个 high 严重度。
- 人工复核:抽取 198 份报告交由人工审阅,其中 89% 的严重度判定与模型自评完全一致——说明它不仅会找,对"这个洞有多危险"的判断也相当靠谱,不会用海量误报淹没防守方。
- 成本区间:单个漏洞从不到 50 美元,到某一整类漏洞约 1 万美元不等。
89% 这个数字的分量不亚于总量。一个会找洞但乱标严重度的工具,对防守方只是噪声;只有"危险程度也判得准"的工具,才同时具备攻击价值和防御价值。
六、负责任披露:为什么 99% 的漏洞没有公开
这种结论极易被用来贩卖焦虑,但报告把披露机制放在了和能力同等重要的位置:
- 报告中展示的漏洞,约 99% 仍未披露、未打补丁——弹药没有一次性倒出。
- 为了既保密、又能在日后自证"我确实早就掌握了它",他们用 SHA-3 密码学承诺占位:先公开一串哈希,等补丁发布后再把哈希替换成真正的漏洞细节。
- 披露遵循 90+45 天窗口:厂商通知后 90 天,必要时再宽限 45 天。
- 所有待披露的发现,都先经专业安全承包商人工验证。
配套启动的 Project Glasswing,目标是把这些发现负责任地交到防守方手里,让防御方先于攻击者做好准备。能力越强,越要看刹车——这套机制至少表明他们认真对待了"先武装谁"的问题。
七、报告给防守方的建议
报告没有止步于展示,而是给了防守方一份务实清单:
- 现在就用起来:不必等待"未来的超级模型",用当下的前沿模型(如 Opus 4.6)做漏洞发现,并趁现在把脚手架和流程搭好,为更强的能力提前练兵。
- 把用法放宽:别只盯着"找洞",把模型用到漏洞三查(triage)、补丁撰写、配置审计、PR 安全评审等环节。
- 从系统层面动手:缩短补丁周期、默认开启自动更新、加快漏洞披露、为无人维护的遗留软件增援资源、把事件响应流水线自动化。
报告把当下定性为一个"分水岭时刻",并主张对计算机安全这门学科做一次从地基开始的重新设计。
结论
 第一,"发现"和"利用"之间那道墙的倒塌,比任何单个数字都重要。 长期以来,"会找洞"和"会用洞"之间隔着稀缺的人类专家,正是这道墙在事实上限制了威胁的规模。当模型能自主从漏洞走到完整 ROP 链、走到双沙箱逃逸,这道墙就被内化进了工具本身——威胁来源从"少数高手"变成了"任何有动机的人加上几十到几千美元"。
第一,"发现"和"利用"之间那道墙的倒塌,比任何单个数字都重要。 长期以来,"会找洞"和"会用洞"之间隔着稀缺的人类专家,正是这道墙在事实上限制了威胁的规模。当模型能自主从漏洞走到完整 ROP 链、走到双沙箱逃逸,这道墙就被内化进了工具本身——威胁来源从"少数高手"变成了"任何有动机的人加上几十到几千美元"。
第二,攻防天平短期偏攻,但卡点不在能力而在流程。 同一个模型,攻击者拿去找洞是即插即用,防守方拿去补洞却要走完测试、灰度、上线全流程。报告"现在就用起来、缩短补丁周期"的建议,本质上是在说:防御方的瓶颈是组织与工程节奏,不是有没有 AI。最终 AI 大概率让防御更强,但中间这段"攻击方已武装、防御方还在搭架子"的窗口期,才是最危险的。
第三,被推到火线上的,是海量无人维护的遗留软件。 OpenBSD 那个洞躺了 27 年、FFmpeg 的躺了 16 年,它们此前的"安全"靠的不是没有漏洞,而是"没人有动力去翻"。当翻一遍的成本降到 50 美元,这层"无人问津的安全"会迅速蒸发。这也是技术平权的双刃面:它让小团队用得起顶级安全分析,也让攻击者用同样的价格批量收割年久失修的代码。
需要说明的是,这是一份预览模型的评估报告,很多关键细节因负责任披露被有意扣住,结论也还需要更多公开复现来检验。但它至少把一件事讲清楚了:AI 在攻防两端同时按下了加速键,而留给防御方搭好框架的时间,可能比多数人预期的更短。
参考资料
- Anthropic 前沿红队,Assessing Claude Mythos Preview's Cybersecurity Capabilities,2026 年 4 月 7 日:https://red.anthropic.com/2026/mythos-preview/
- 文中相关:Project Glasswing(负责任披露)、CVE-2026-4747(FreeBSD NFS RCE)、CVE-2024-47711(一字节内核内存读取)